- TOP
- 製品情報
- NVIDIA データ…
- 製品シリーズ…
- NVIDIA A30
製品情報





- 製品概要
- 仕様
製品概要
あらゆる企業のための AI 推論とメインストリーム コンピューティング
NVIDIA A30 Tensor コア GPU は、企業のあらゆるワークロードのパフォーマンスを高速化します。
NVIDIA Ampere アーキテクチャの Tensor コアとマルチインスタンス GPU (MIG) で、大規模な AI 推論や
ハイパフォーマンス コンピューティング (HPC) アプリケーションといった、多様なワークロードを安全に高速化します。
PCI Expressフォーム ファクターに高速のメモリ帯域幅と少ない電力消費が組み合わされており、メインストリーム サーバーに
最適です。A30 はエラスティック データ センターを実現し、企業に最大限の価値をもたらします。
![]()
現代の IT に合うデータ センター ソリューション
NVIDIA Ampere アーキテクチャは、統合された NVIDIA EGX™ プラットフォームの一部であり、ハードウェア、ネットワーキング、ソフトウェア、ライブラリ、そして NVIDIA NGC™ カタログ内の最適化された AI モデルとアプリケーションのビルディング ブロックを組み合わせます。データ センター向けとして最もパワフルなエンドツーエンド AI/HPC プラットフォームであり、研究者は短期間で実際の成果をあげ、ソリューションを大規模な運用環境に展開できます。
ディープラーニング トレーニング
AI トレーニング— v100 の 3 倍、T4 の 6倍のスループット
BERT Large ファインチューニング、収束までの時間
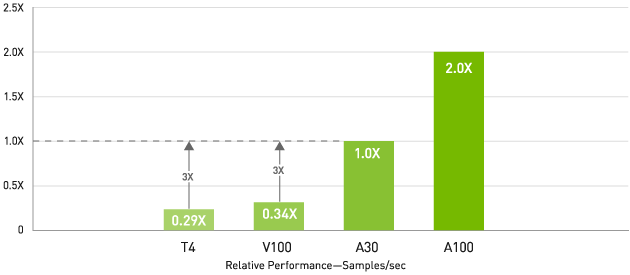
ERT-Large
Pre-Training (9/10 エポック) フェーズ 1 および (1/10 エポック) フェーズ 2、シーケンス長: フェーズ 1 = 128 およびフェーズ 2 = 512、データセット =
real、NGC™ コンテナー = 21.03、
8x GPU: T4 (FP32、BS=8、2)、V100 PCIE 16GB (FP32、BS=8、2)、A30 (TF32、BS=8、2)、A100 PCIE 40GB
(TF32、BS=54、8)。示されているバッチ サイズはそれぞれフェーズ 1 用とフェーズ 2 用
Pre-Training (9/10 エポック) フェーズ 1 および (1/10 エポック) フェーズ 2、シーケンス長: フェーズ 1 = 128 およびフェーズ 2 = 512、データセット =
real、NGC™ コンテナー = 21.03、
8x GPU: T4 (FP32、BS=8、2)、V100 PCIE 16GB (FP32、BS=8、2)、A30 (TF32、BS=8、2)、A100 PCIE 40GB
(TF32、BS=54、8)。示されているバッチ サイズはそれぞれフェーズ 1 用とフェーズ 2 用
対話型 AI といった次のレベルの課題に向けて AI モデルをトレーニングするには、膨大な演算能力とスケーラビリティが必要です。
NVIDIA A30 Tensor コア と Tensor Float (TF32)を利用することで、NVIDIA T4 と比較して最大 10 倍のパフォーマンスがコードを変更することなく得られます。加えて、Automatic Mixed Precision と FP16 の活用でさらに 2倍の高速化が可能になります。スループットは合わせて 20 倍増えます。 NVIDIA® NVLink®、PCIe Gen4、NVIDIA Mellanox® ネットワーキング、 NVIDIA Magnum IO™SDK と組み合わせることで、数千の GPU までスケールできます。
Tensor コアと MIG により、A30 はいつでも柔軟にワークロードを処理できます要求がピークのときには本稼働推論に使用し、オフピーク時には一部の GPU を転用して同じモデルを高速で再トレーニングできます。
NVIDIA は、AI トレーニングの業界標準ベンチマークである MLPerf で複数のパフォーマンス記録を打ち立てています。
トレーニング向け NVIDIAAmpereアーキテクチャの詳細を見る ›
ディープラーニング推論
A30 には、推論ワークロードを最適化する画期的な機能が導入されています。FP64 から TF32 や INT4 まで、あらゆる精度を加速します。GPU あたり最大 4 つのMIG をサポートする A30 では、安全なハードウェア パーティションで複数のネットワークを同時に運用でき、サービス品質 (QoS) が保証されます。また、スパース構造により、A30による数々の推論パフォーマンスの向上に加え、さらに最大 2 倍のパフォーマンスがもたらされます。
市場をリードする NVIDIA の AI パフォーマンスは MLPerf 推論で実証されました。AI を簡単に大規模展開する NVIDIA Triton™ 推論サーバーとの組み合わせで、A30 はあらゆる企業に圧倒的なパフォーマンスをもたらします。
推論向け NVIDIA Ampere アーキテクチャの詳細を見る ›
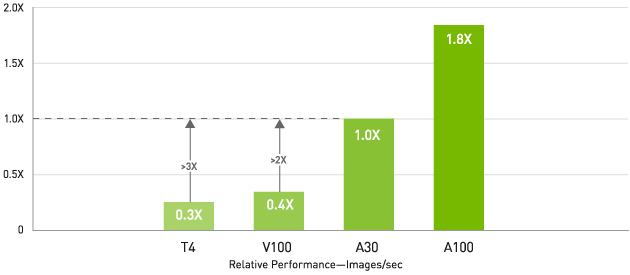
AI推論-リアルタイム対話型AIでV100と比較してスループットが最大3倍
BERT Large 推論 (正規化済み)
レイテンシ10ms未満でのスループット
NVIDIA®
TensorRT®、精度 = INT8、シーケンス長 = 384、NGC コンテナー = 20.12、レイテンシ < 10 ms、データセット = 合成、1x GPU: A100 PCIE 40 GB (BS
= 8) | A30 (BS = 4) | V100 SXM2 16 GB | T4 (BS = 1)
TensorRT®、精度 = INT8、シーケンス長 = 384、NGC コンテナー = 20.12、レイテンシ < 10 ms、データセット = 合成、1x GPU: A100 PCIE 40 GB (BS
= 8) | A30 (BS = 4) | V100 SXM2 16 GB | T4 (BS = 1)
AIトレーニング—v100の3倍、T4の6倍のスループット
RN50 v1.5推論 (正規化)
7ms以下のレイテンシでのスループット
TensorRT, NGC
Container 20.12, Latency <7ms, Dataset=Synthetic, 1x GPU: T4 (BS=31, INT8) | V100 (BS=43, Mixed
precision) | A30 (BS=96, INT8) | A100 (BS=174, INT8)
Container 20.12, Latency <7ms, Dataset=Synthetic, 1x GPU: T4 (BS=31, INT8) | V100 (BS=43, Mixed
precision) | A30 (BS=96, INT8) | A100 (BS=174, INT8)
ハイパフォーマンス コンピューティング
HPC — V100 と比較して最大 1.1 倍、T4 と比較して 8 倍のスループット
LAMMPS (正規化済み)
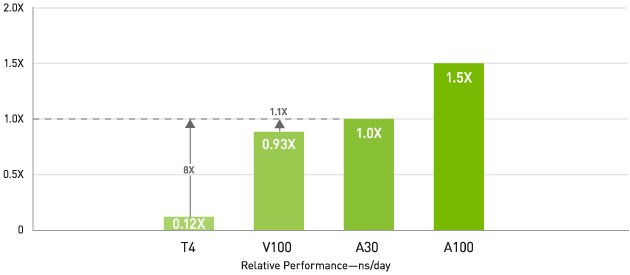
データセット: ReaxFF/C、FP64 | 4x GPU: T4、V100 PCIE 16 GB、A30
科学者たちは次世代の発見のため、私たちを取り巻いている世界をより良く理解しようと、シミュレーションに関心を向けています。
NVIDIA A30 は FP64 の NVIDIA Ampere アーキテクチャ Tensor コアを備えています。これは、GPU の導入以来の、HPC パフォーマンスにおける最大級の飛躍です。帯域幅が毎秒 933 ギガバイト (GB/s) の GPU メモリ 24 ギガバイト (GB) との組み合わせにより、研究者は倍精度計算を短時間で解決できます。HPC アプリケーションで TF32 を活用すれば、単精度の密行列積演算のスループットを上げることができます。
FP64 Tensor コアと MIG の組み合わせにより、研究機関は、GPU を安全に分割して複数の研究者がコンピューティング リソースを利用できるようにし、QoS を保証し、GPU 使用率を最大限まで高めることができます。AI を展開している企業は要求のピーク時に A30 を推論に利用し、オフピーク時には同じコンピューティング サーバーを HPC や AI トレーニングのワークロードに転用できます。
ハイパフォーマンス データ分析
データ サイエンティストは、大量のデータセットを分析し、可視化し、インサイトに変えられる能力を求めています。しかしながら、スケールアウト ソリューションは行き詰まることが多々あります。複数のサーバー間でデータセットが分散されるためです。
A30 搭載のアクセラレーテッド サーバーは、必要とされる演算能力、HBM2 大容量メモリ、毎秒 933 GB のメモリ帯域幅、NVLink によるスケーラビリティをもたらし、こうしたワークロードに対処します。 NVIDIA InfiniBand、NVIDIA Magnum IO 、RAPIDS™ オーブンソース ライブラリ スイート (RAPIDS Accelerator for Apache Spark を含む) との組み合わせにより、NVIDIA データ センター プラットフォームは、かつてないレベルのパフォーマンスと効率性で、こうした巨大なワークロードを高速化します。
企業クラスの使用率

A30 と MIG の組み合わせは、GPU 対応インフラストラクチャの使用率を最大限に高めます。MIG を利用することで、A30 GPU を 4 つもの独立したインスタンスに分割できます。複数のユーザーが GPU アクセラレーションを利用できます。
MIG は、Kubernetes、コンテナー、 ハイパーバイザーベースのサーバー仮想化と連動します。MIG を利用することで、インフラストラクチャ管理者はあらゆるジョブに適切なサイズの GPU を提供し、QoS を保証できます。アクセラレーテッド コンピューティング リソースをすべてのユーザーに届けることが可能になります。
NVIDIA AI ENTERPRISE
NVIDIA AI Enterprise は、AI とデータ分析ソフトウェアのエンドツーエンドのクラウドネイティブ スイートです。VMware vSphere が含まれるハイパーバイザーベースの仮想インフラストラクチャにおいて、A30 上で実行できることが認定されています。これにより、ハイブリッド クラウド環境で AI ワークロードを管理、拡張できます。


メインストリームの NVIDIA-CERTIFIED SYSTEMS
NVIDIA-Certified Systems™ と NVIDIA A30 の組み合わせにより、NVIDIA の OEM パートナーが構築および販売するエンタープライズ データ センター サーバーでは、コンピューティングが加速するうえ、高速かつ安全な NVIDIA ネットワーキングを利用することもできます。このプログラムでは、費用対効果が高くスケーラブルな 1 つの高性能インフラストラクチャで、NVIDIA NGC カタログ内のオーソドックスな AI アプリケーションと多彩な最新式 AI アプリケーションのためのシステムを特定、入手、展開できます。
仕様
| CUDA Cores | 非公開 |
|---|---|
| Tensor Cores | 非公開(第3世代) |
| RT Cores | N/A |
| GPU クロック(MHz) | ベース: 930 |
| ブースト: 1440 | |
| メモリ容量 | 24GB HBM2 |
| メモリインターフェイス(bit) | 3072 |
| メモリクロック(MHz) | 1215 |
| メモリ帯域幅(GB/s) | 933 |
| 対応拡張スロット | PCI Express 4.0 x16 |
| コンピュートAPI | NVIDIA CUDA / DirectCompute / OpenCL / OpenACC |
| 出力コネクタ | N/A |
| グラフィックスAPI | N/A |
| 適合規格 | WHQL / ISO9241 / EU RoHS / JIG / REACH / HF / WEEE / RCM / BSMI /CE / FCC / ICES / KC / cUL, UL / VCCI |
| 対応OS | Windows Server 2019, Windows Server 2022, Windows10 64bit(*1) , Windows11, Linux 64bit |
| 最大消費電力 | 165 W |
| 補助電源コネクタ仕様 | CPU 8pin(*2) |
| 外形寸法(mm) ブラケット含まず |
267.7 x 111.2、ATX、2スロットサイズ |
| 付属品 | PCIe 8pin×2 – CPU 8pin x1 補助電源変換ケーブル × 1 |
(*1) バージョン1809以降を推奨
(*2) 6ピン/8ピンのPCI Express用補助電源とCPU 8ピン補助電源コネクタは形状が異なります。
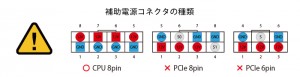
必要動作環境
本製品はNVIDIA社の認定システムのみの動作保証となります。
詳しくは下記リンク先の情報をご確認ください。
https://www.nvidia.com/ja-jp/data-center/data-center-gpus/qualified-system-catalog/
理論演算性能値
| FP64 (TFLOPS) | 5.2 | |
|---|---|---|
| FP64 Tensor Core (TFLOPS) | 10.3 | |
| FP32 (TFLOPS) | 10.3 | |
| FP16 (TFLOPS) | 41.2 | |
| TF32 Tensor Core (TFLOPS) | 82 | 165(*3) |
| BFLOAT16 Tensor Core (TFLOPS) | 165 | 330(*3) |
| FP16 Tensor Core (TFLOPS) | 165 | 330(*3) |
| INT8 Tensor Core (TOPS) | 330 | 661(*3) |
| INT4 Tensor Core (TOPS) | 661 | 1321(*3) |
(*3) 構造化スパースを適用
対応機能
| Multi-Instance GPU Support (Max Instance) | 〇(4) |
|---|---|
| ECC 対応 | 〇 |
| NVLink 対応 | 200GB/s (第3世代) |
製品内容
- NVIDIA A30
- 製品保証書
保証期間
- 3年間保証
製品名・型番・JANコード
| 製品名 | NVIDIA A30 NC | NVIDIA A30 |
|---|---|---|
| 型番 | ETSA30-24GER2 | ETSA30-24GER |
| JANコード | 4524076071352 | 4524076071178 |
■本製品は順次製品名に「NC」が付くものへ置き換わり、「NC」が付かないものは在庫が無くなり次第終息とさせていただきます。
■製品名に「NC」が付くものは、製品の機能からCECが削除されます。
※CECとは
CECはGPUボード上のセカンダリRoT(root of trust)のことで、 デバイスの信頼性を保証するためのハードウェア / ソフトウェアコンポーネントを指します。
また、CECの廃止に伴い以下の機能が提供されなくなります。
- ファームウェア署名キー
- ファームウェアの正当性証明
- Out-of-band ファームウェアアップデート
価格
- オープンプライス
オプション製品
A30用NVLinkブリッジ
| 型番 | P3412 |
|---|---|
| 製品名 | NVIDIA NVLink Bridge 2-Slot for Ampere Retail |
| JAN コード | 4524076030311 |
© NVIDIA Corporation. All Rights Reserved. NVIDIA, NVIDIA logo, Tesla, and CUDA are registered trademarks and/or trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.