特設ページ
NVIDIA A100ソリューション

現代で最も重要な作業を高速化
NVIDIA A100 Tensor コア GPU によるあらゆるスケールでの前例のない高速化をもって、世界で最も困難な計算に AI、データ分析、 HPC で挑むことができます。NVIDIA データ センター プラットフォームのエンジン A100 は、数千単位の GPU に効果的に拡張できます。あるいは、NVIDIA マルチインスタンス GPU (MIG) テクノロジを利用し、7 個の GPU インスタンスに分割し、あらゆるサイズのワークロードを加速できます。また、第 3 世代 Tensor コアでは、多様なワークロードであらゆる精度が高速化され、洞察を得るまでの時間と製品を市場に届けるまでの時間が短縮されます。
AI と HPC の最もパワフルなエンドツーエンド データ センター プラットフォーム
A100 は 、ハードウェア、ネットワーキング、ソフトウェア、ライブラリ、最適化された AI モデル、 NGC™ のアプリケーションにわたる構成要素を組み込んだ NVIDIA の完全データ センター ソリューション スタックの一部です。データ センター向けとして最もパワフルな AI/HPC 用エンドツーエンド プラットフォームであり、研究者は現実世界で成果をもたらし、ソリューションを大規模な運用環境に展開できます。
ディープラーニング トレーニング
正確に会話する AI やディープ リコメンダー システムなど、次のレベルの課題に挑むため、AI モデルの複雑性が爆発的に増しています。
モデルのトレーニングには、大規模な計算処理能力とスケーラビリティが必要になります。
NVIDIA A100 の第 3 世代 Tensor コア と Tensor Float (TF32) 精度を利用することで、前世代と比較して最大 20 倍のパフォーマンスがコードを変更することなく得られ、Automatic Mixed Precision (AMP) と FP16 の活用でさらに 2 倍の高速化が可能になります。第 3 世代 NVIDIA® NVLink®、NVIDIA NVSwitch™、PCI Gen4、NVIDIA Mellanox InfiniBand、NVIDIA Magnum IO ソフトウェア SDK の組み合わせで、数千単位の A100 GPU まで拡張できます。拡張することで、BERT のような大型の AI モデルを 1,024 個の A100 からなるクラスターでわずか 37 分でトレーニングできます。このパフォーマンスとスケーラビリティには前例がありません。トレーニングにおける NVIDIA の優位性は MLPerf 0.6 で実証されました。これは業界全体で使える初の AI トレーニング向けベンチマークです。
AI トレーニング向けの TF32 を使用して、設定不要で最大 6 倍高速な性能を実現
BERT トレーニング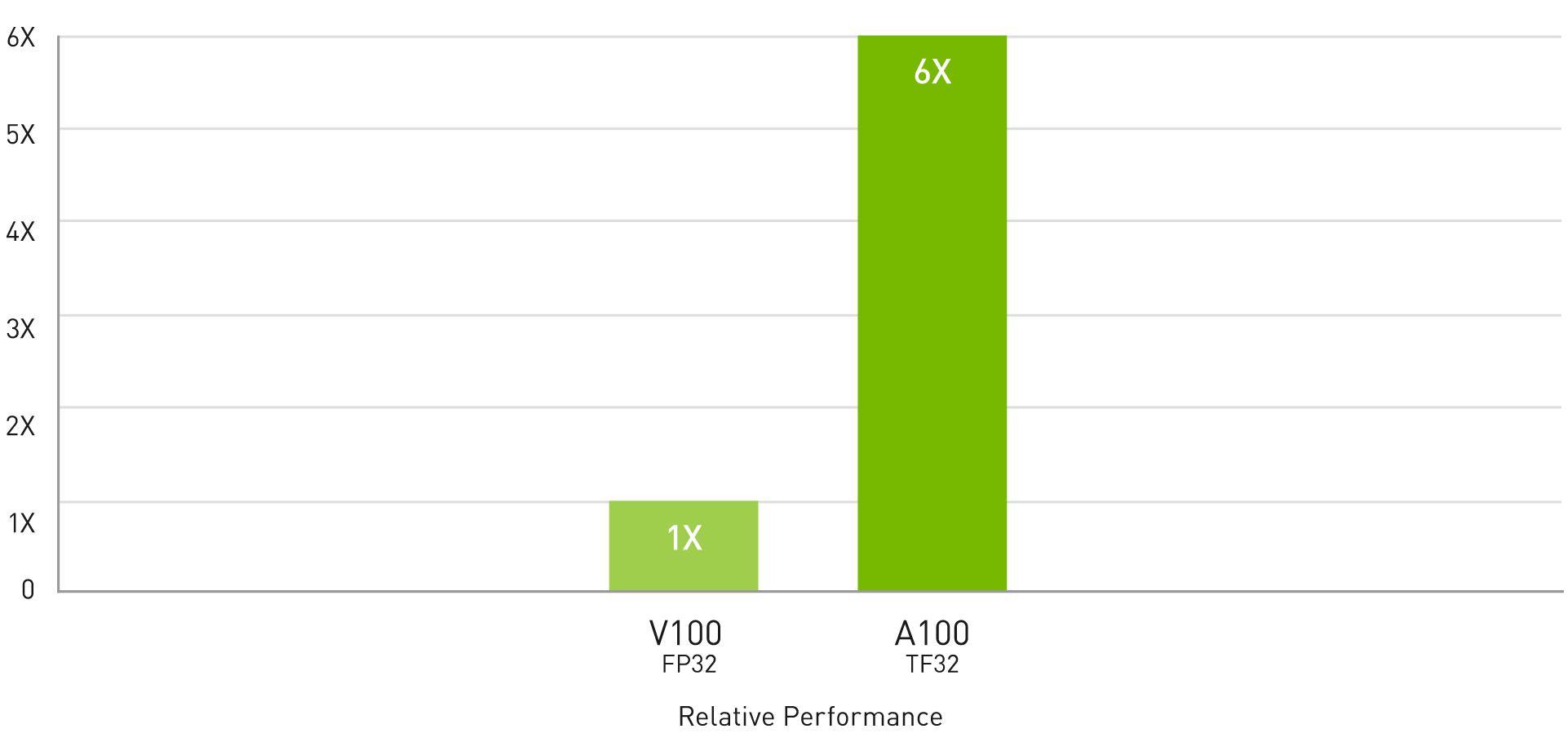
BERT pre-training throughput using Pytorch, including (2/3) Phase 1 and (1/3) Phase 2 | Phase 1 Seq Len = 128, Phase 2 Seq Len = 512; V100: NVIDIA DGX-1™ server with 8x V100 using FP32 precision; A100: DGX A100 Server with 8x A100 using TF32 precision.
ディープラーニング推論
A100 には、推論ワークロードを最適化する画期的な新機能が導入されています。その汎用性には前例がなく、FP32 から FP16、INT8 に INT4 まで、あらゆる精度を加速します。 マルチインスタンス GPU (MIG) テクノロジでは、1 個の A100 GPU で複数の AI モデルを同時に運用できるため、計算リソースの使用を最適化できます。また、A100 の数々の推論高速化は、スパース行列演算機能によってさらに 2 倍の性能を発揮します。
業界初の推論用ベンチマークである MLPerf Inference 0.5 ですべて制覇したことからわかるように、NVIDIA は市場をリードする推論パフォーマンスをすでに成し遂げています。A100 はパフォーマンスを 10 倍にし、そのリードをさらに広げます。
AI 推論のためのマルチインスタンス GPU (MIG) により最大 7 倍高速な性能を実現
BERT 大規模推論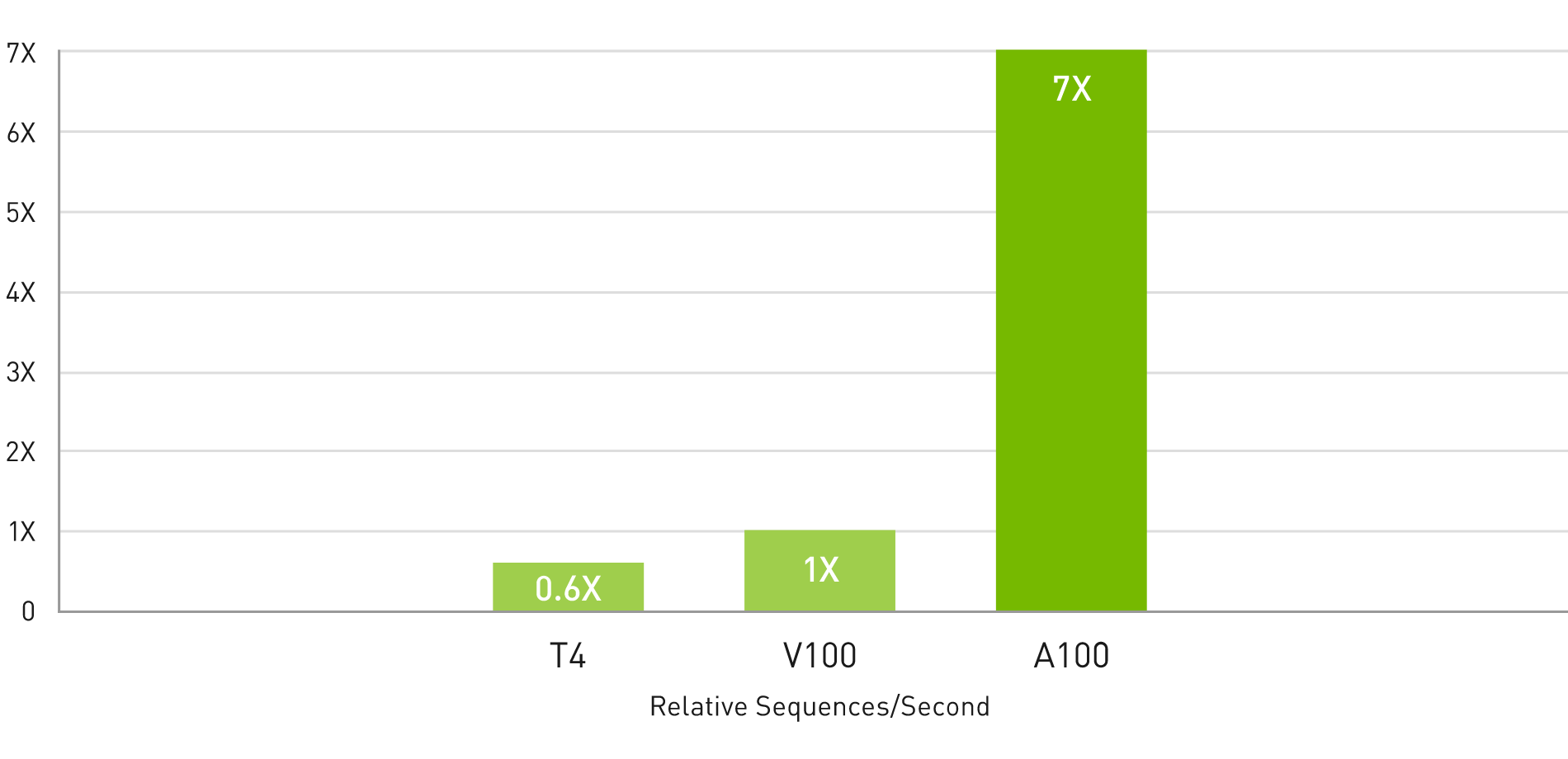
BERT Large Inference | NVIDIA T4 Tensor Core GPU: NVIDIA TensorRT™ (TRT) 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 7 MIG instances of 1g.5gb: pre-production TRT, batch size = 94, precision = INT8 with sparsity.
ハイパフォーマンス コンピューティング
次世代の新しい技術を開発するために、サイエンティストたちは複雑な分子に対する理解度を上げるシミュレーションを求めています。そのシミュレーションによって薬を発見したり、物理学から新しいエネルギー源の可能性を探ったり、大気データから極端な天候パターンを今までより高い精度で予測し、それに備えたりします。A100 には倍精度の Tensor CoresTensor コア が搭載されています。HPC 向けの GPU で倍精度演算を導入して以来、最大の画期的出来事です。これにより、研究者たちは、NVIDIA V100 Tensor コア GPU で 10 時間を要していた倍精度シミュレーションを、A100 でたった 4 時間に短縮できます。HPC アプリケーションではまた、A100 の Tensor コアで TF32 精度を活用し、単精度の密行列積で最大 10 倍の演算スループットを実現できます。
4 年間で 9 倍の HPC パフォーマンス
上位 HPC アプリケーションのスループット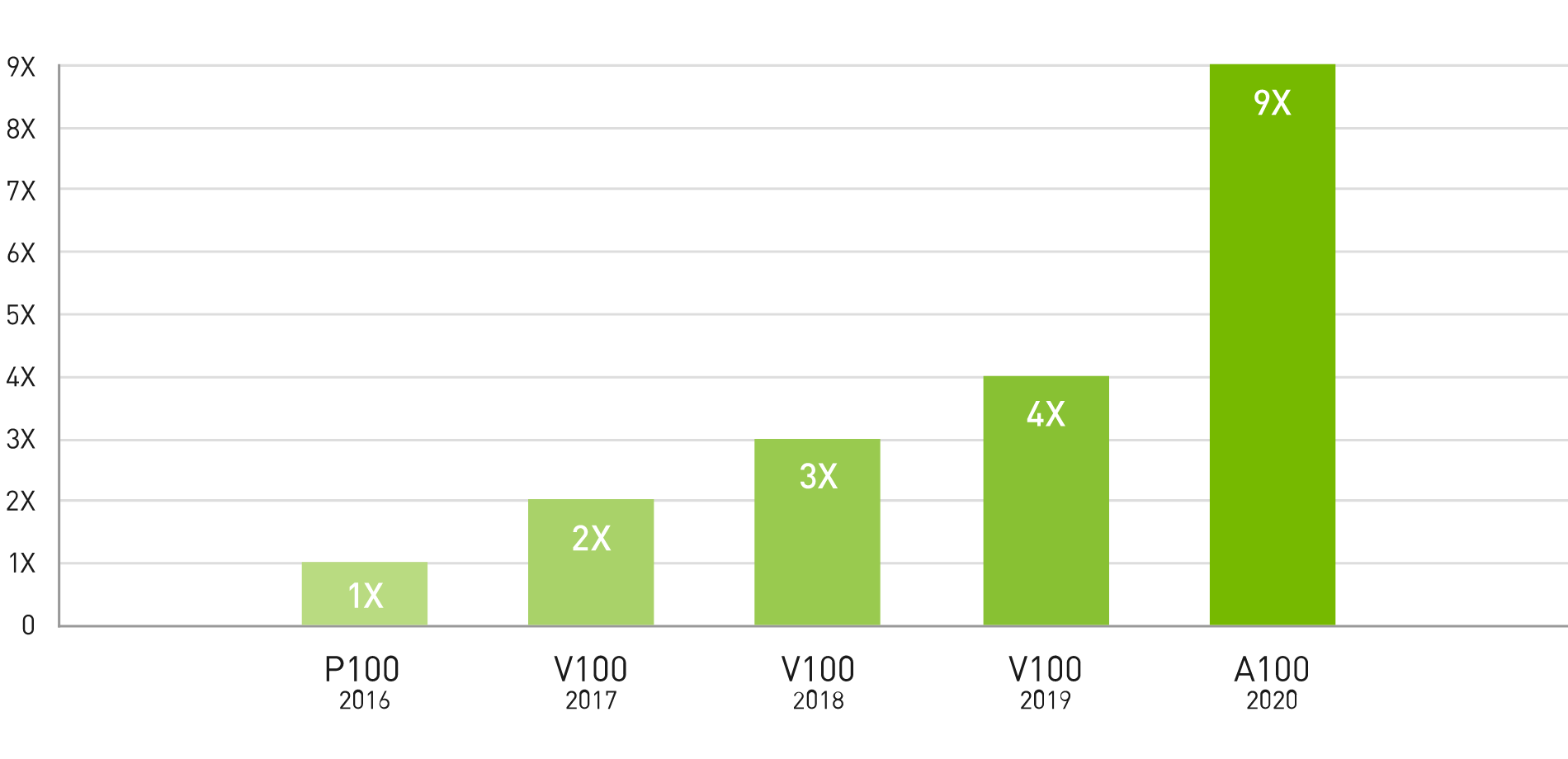
Geometric mean of application speedups vs. P100: benchmark application: Amber [PME-Cellulose_NVE], Chroma [szscl21_24_128], GROMACS [ADH Dodec], MILC [Apex Medium], NAMD [stmv_nve_cuda], PyTorch (BERT Large Fine Tuner], Quantum Espresso [AUSURF112-jR]; Random Forest FP32 [make_blobs (160000 x 64 : 10)], TensorFlow [ResNet-50], VASP 6 [Si Huge], | GPU node with dual-socket CPUs with 4x NVIDIA P100, V100, or A100 GPUs.
ハイパフォーマンス データ分析
顧客は、大量のデータセットを分析し、可視化し、洞察に変えることを求めています。しかしながら、スケールアウト ソリューションは行き詰まることが多々あります。複数のサーバー間でデータセットが分散されるためです。A100 を搭載したアクセラレーテッド サーバーなら、要求される計算処理能力のほか、毎秒 1.6 テラバイト (TB/秒) のメモリ帯域幅、第 3 世代 NVLink と NVSwitch によるスケーラビリティがもたらされ、大規模なワークロードに取り組むことができます。Mellanox InfiniBand、Magnum IO SDK、GPU 対応 Spark 3.0、 GPU 活用データ分析用のソフトウェア スイートである RAPIDS™ との組み合わせにより、 NVIDIA データ センター プラットフォームは、画期的なレベルの比類なきパフォーマンスと効率で非常に大規模なワークロードを加速することができます。
企業で効率的に利用
A100 と MIG の組み合わせにより、GPU 対応インフラストラクチャを今までにないレベルで最大限に活用できます。MIG によって A100 GPU は最大 7 つの独立したインスタンスに分割でき、複数のユーザーが自分のアプリケーションや開発プロジェクトを GPU で高速化できます。MIG は Kubernetes やコンテナー、ハイパーバイザベースのサーバー仮想化によるNVIDIA Virtual Compute Server(vComputeServer) と連携します。 MIG を使用することで、インフラ管理者は各ジョブのサービス品質 (QoS) を保証した適切なサイズの GPU を提供し、使用率を最適化し、高速化されたコンピューティング リソースの範囲をすべてのユーザーに拡大することができます。
マルチインスタンス GPU (MIG) による 7 倍の推論スループット
BERT 大規模推論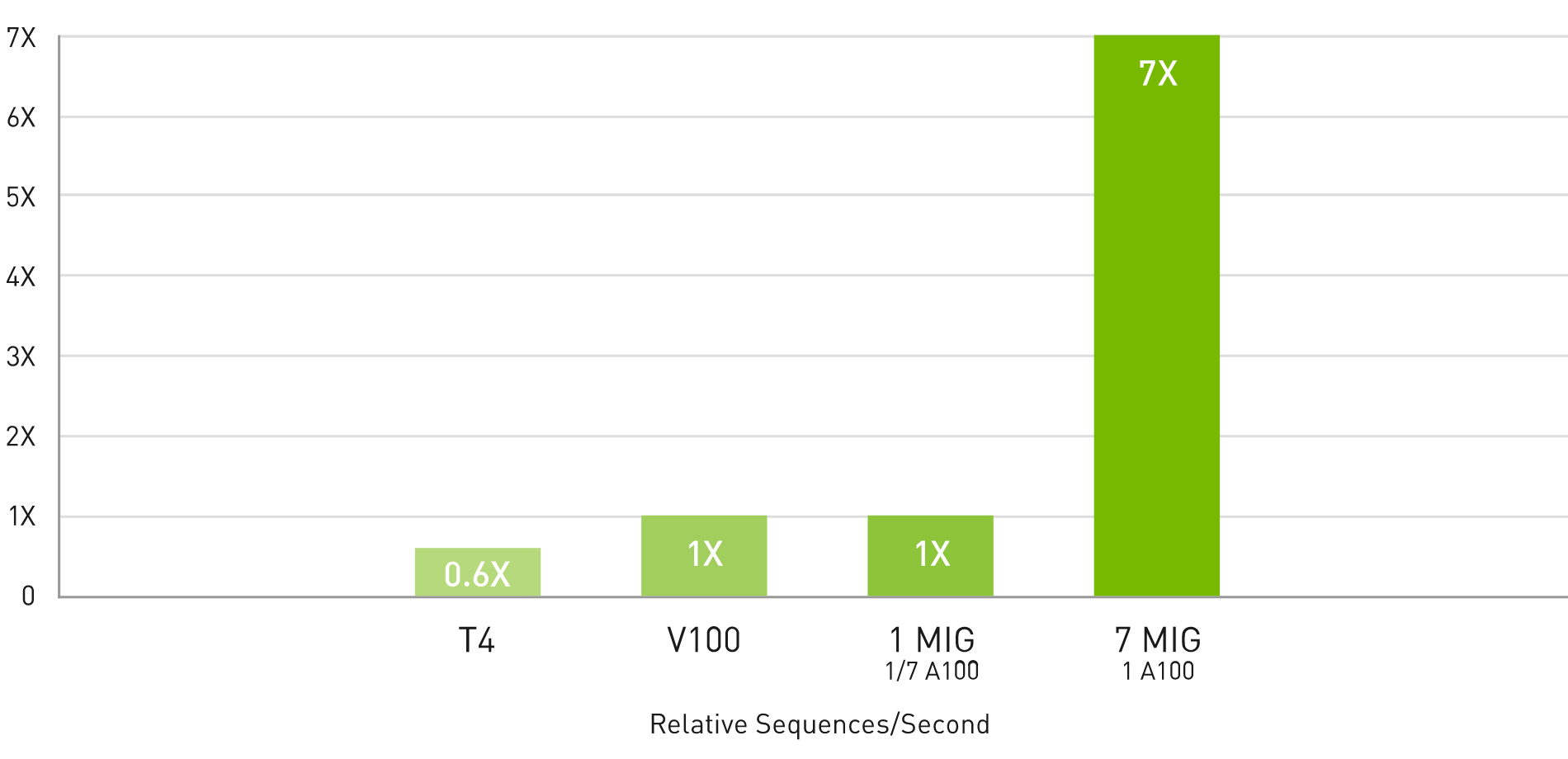
BERT Large Inference | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = INT8 with sparsity.
データセンター GPU

|

|
HGX 向け NVIDIA A100 すべてのワークロードに対応する究極のパフォーマンス。 |
PCIe 向け NVIDIA A100 すべてのワークロードに対応する最高の汎用性。 |
仕様
| HGX 向け NVIDIA A100 | PCIe 向け NVIDIA A100 | |
| ピークFP64 | 9.7 TF | |
| ピークFP64 Tensor コア | 19.5 TF | |
| ピークFP32 | 19.5 TF | |
| ピークTF32 Tensor コア | 156 TF | 312 TF* | |
| ピークBFLOAT16 Tensor コア | 312 TF | 624 TF* | |
| ピークFP16 Tensor コア | 312 TF | 624 TF* | |
| ピークINT8 Tensor コア | 624 TOPS | 1,248 TOPS* | |
| ピークINT4 Tensor コア | 1,248 TOPS | 2,496 TOPS* | |
| GPUメモリ | 40 GB | |
| GPUメモリ帯域幅 | 1,555 GB/s | |
| 相互接続 | NVIDIA NVLink 600 GB/s** PCIe Gen4 64 GB/s |
|
| マルチインスタンス GPU | 最大7MIG @5GBのさまざまなインスタンスサイズ | |
| フォームファクター | 4/8 SXM on NVIDIA HGX™ A100 | PCIe |
| 最大TDP電力 | 400W | 250W |
| 主要アプリケーション 実効性能 |
100% | 90% |
* スパース行列の場合
** HGX A100 サーバー ボード経由の SXM GPU、最大 2 GPU の NVLink ブリッジ経由の PCIe GPU
NVIDIA A100搭載サーバー
