- TOP
- ソリューションサイト
- NVIDIA H100 Tensor コア GPU
NVIDIA H100 Tensor コア GPU
アクセラレーテッド コンピューティングの大きな飛躍
NVIDIA H100 Tensor コア GPU で、あらゆるワークロードのためのかつてない性能、拡張性、セキュリティを手に入れましょう。
エンタープライズ AI の準備はできていますか?
企業における AI の導入はもはや主流になっており、企業はこの新時代に向けて組織を加速させるエンドツーエンド の AI 対応インフラストラクチャを必要としています。
標準サーバー向けの H100 には、NVIDIA AI Enterprise ソフトウェア スイートのサブスクリプション 5 年分 (エンタープライズ サポートなど) が付属しており、その非常に優れた性能によって AI を簡単に導入できます。それにより、企業や組織は、AI チャットボット、レコメンデーション エンジン、ビジョン AI など、H100 で高速化する AI ワークフローを構築するために必要な AI フレームワークおよびツールが活用できるようになります。
最大規模のモデルで AI 推論性能を最大 30 倍に。
Megatron チャットボット推論 (5300 億個のパラメーター)
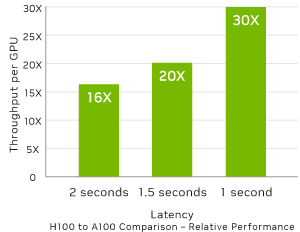 Projected performance subject to change. Inference on Megatron 530B parameter model chatbot for input sequence length=128, output sequence length=20 | A100 クラスター: HDR IB ネットワーク | H100 クラスター: 16 個の H100 構成のための NDR IB ネットワーク | 1 秒と 1.5 秒の場合の 32 A100 と 16 H100 の比較 | 2 秒の場合の 16 A100 と 8 H100 の比較
Projected performance subject to change. Inference on Megatron 530B parameter model chatbot for input sequence length=128, output sequence length=20 | A100 クラスター: HDR IB ネットワーク | H100 クラスター: 16 個の H100 構成のための NDR IB ネットワーク | 1 秒と 1.5 秒の場合の 32 A100 と 16 H100 の比較 | 2 秒の場合の 16 A100 と 8 H100 の比較
リアルタイムのディープラーニング推論。
AI は、さまざまなビジネスの課題を、同じくらいさまざまなニューラル ネットワークを使用して解決します。優れた AI 推論アクセラレータには、最高のパフォーマンスだけでなく、様々なネットワークを加速するための多様性も求められます。
H100 では、推論が最大 30 倍高速化になる、レイテンシが最小限に抑えられるなど、機能が強化されます。それにより、市場をリードする NVIDIA の推論のリーダーシップをさらに拡大します。第 4 世代の Tensor コアは FP64、TF32、FP32、FP16、INT8 など、あらゆる精度をスピードアップします。Transformer Engine は FP8 と FP16 の両方を活用してメモリ消費を減らしてパフォーマンスを増やしつつ、大規模な言語モデルで精度を維持します。
HPC アプリケーションのパフォーマンスが最大 7 倍に。
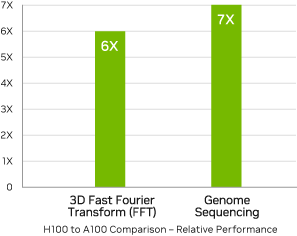 予想されるパフォーマンスは変更される可能性があります。3D FFT (4K^3) スループット | A100 クラスター: HDR IB ネットワーク | H100 クラスター: NVLink スイッチ システム、NDR IB | ゲノム シーケンシング (Smith-Waterman) | 1 A100 | 1 H100
予想されるパフォーマンスは変更される可能性があります。3D FFT (4K^3) スループット | A100 クラスター: HDR IB ネットワーク | H100 クラスター: NVLink スイッチ システム、NDR IB | ゲノム シーケンシング (Smith-Waterman) | 1 A100 | 1 H100
エクサスケール ハイパフォーマンス コンピューティング。
NVIDIA データ センター プラットフォームは、ムーアの法則を超えるパフォーマンス向上を継続的に提供します。また、H100 の新しい画期的な AI 機能は、HPC+AI のパワーをさらに増幅し、世界の最重要課題の解決に取り組む科学者や研究者にとって、発見までの時間が加速されます。
H100 は、倍精度 Tensor コアの毎秒浮動小数点演算 (FLOPS) を 2.6 倍にし、HPC で 50 teraFLOPS の FP64 コンピューティングを実現します。AI と融合した HPC アプリケーションでは、H100 の TF32 精度を活用し、コードの変更なしに、単精度行列乗算演算で 700 teraFLOP のスループットを達成することができます。
H100 はまた、DPX 命令を備え、NVIDIA A100 Tensor コア GPU の 7 倍のパフォーマンスを提供し、DNA シーケンス アライメント用の Smith-Waterman など、動的プログラミング アルゴリズムにおいて従来のデュアルソケット CPU のみのサーバーと比較して 40 倍の高速化を実現します。

データ分析の高速化。
データ分析は多くの場合、AI アプリケーションの開発時間の大半を占めます 大規模なデータセットは複数のサーバーに分散されるため、CPU だけの市販のサーバーによるスケールアウト ソリューションでは、スケーラブルなコンピューティング パフォーマンスに欠け、動かなくなります。
H100 で高速化するサーバー、GPU ごとに毎秒 2 テラバイトのメモリ帯域幅、NVLink によるスケーラビリティなら、膨大なデータセットに対処するハイパフォーマンスとスケールでデータを分析できます。NVIDIA Quantum-2 Infiniband、Magnum IO ソフトウェア、GPU 高速化 Spark 3.0、NVIDIA RAPIDS™ と組み合わせることで、NVIDIA データ センター プラットフォームは、比類なきレベルのパフォーマンスと効率性で膨大なワークロードを、他にはない方法で、高速化できます。
企業で効率的に利用。
IT マネージャーはデータ センターでコンピューティング リソースの利用率 (ピークと平均の両方) を最大化することを求めます。多くの場合、コンピューティングを動的に再構成し、使用中のワークロードに合わせてリソースを正しいサイズに変更します。
H100 の第 2 世代 マルチ インスタンス GPU (MIG) では、7 個ものインスタンスに分割することで各 GPU の利用率を最大化します。コンフィデンシャル コンピューティング対応の H100 では、マルチテナントをエンドツーエンドで安全に利用できます。クラウド サービス プロバイダー (CSP) 環境に最適です。
H100 と MIG なら、インフラストラクチャ管理者は GPU アクセラレーテッド インフラストラクチャを標準化できて、同時に、GPU リソースを非常に細かくプロビジョニングできます。正しい量のアクセラレーテッド コンピューティングが安全に開発者に与えられ、GPU リソースの利用を最適化します。
コンフィデンシャル コンピューティングを内蔵。
今日のコンフィデンシャル コンピューティング ソリューションは CPU ベースで、AI や HPC など、大量の計算処理を必要とするワークロードの場合、十分ではありません。NVIDIA コンフィデンシャル コンピューティングは NVIDIA Hopper™ アーキテクチャの組み込みセキュリティ機能です。H100 を、コンフィデンシャル コンピューティング機能のある世界初のアクセラレータにしたのがこのアーキテクチャです。ユーザーは使用中のデータとアプリケーションの機密性と完全性を保護し、同時に、H100 GPU の卓越した高速化を利用できます。ハードウェアベースの TEE (Trusted Execution Environment/信頼できる実行環境) を作り、1 個の H100 GPU で、1 個のノード内の複数の H100 GPU で、または個々の MIG インスタンスで実行されるワークロード全体をセキュリティで保護し、隔離します。GPU で高速化するアプリケーションは、何も変更せずに TEE 内で実行できます。また、分割する必要がありません。ユーザーは AI と HPC のための NVIDIA ソフトウェアのパワーと、NVIDIA コンフィデンシャル コンピューティングから与えられるハードウェア RoT (Root of Trust/信頼の起点) のセキュリティを組み合わせることができます。
製品仕様
| フォーム ファクター | H100 PCIe |
|---|---|
| FP64 | 26 teraFLOPS |
| FP64 Tensor コア | 51 teraFLOPS |
| FP32 | 51 teraFLOPS |
| TF32 Tensor コア | 756teraFLOPS* |
| BFLOAT16 Tensor コア | 1,513 teraFLOPS* |
| FP16 Tensor コア | 1,513 teraFLOPS* |
| FP8 Tensor コア | 3,026 teraFLOPS* |
| INT8 Tensor コア | 3,026 TOPS* |
| GPU メモリ | 80GB |
| GPU メモリ帯域幅 | 2TB/秒 |
| デコーダー | 7 NVDEC 7 JPEG |
| 最大熱設計電力 (TDP) | 300–350W (構成可能) |
| マルチインスタンス GPU | 最大 7 個の MIG @ 10GB |
| フォーム ファクター | PCIe デュアルスロット空冷 |
| 相互接続 | NVLINK: 600GB/秒 PCIe Gen5: 128GB/秒 |
| サーバー オプション | 1~8 GPU 搭載のパートナーおよび NVIDIA Certified Systems™ |
| NVIDIA AI Enterprise | 含む |