- TOP
- 製品情報
- NVIDIA データ センター GPU
- 製品シリーズ一覧
- NVIDIA A100(80GB)
製品情報
NVIDIA A100(80GB)







- 製品概要
- 仕様
製品概要
現代で最も重要な作業を高速化
NVIDIA A100 Tensorコア GPUはあらゆる規模で前例のない高速化を実現し、世界最高のパフォーマンスを誇るエラスティックデータセンターに AI、データ分析、HPCのためのパワーを与えます。NVIDIA Ampereアーキテクチャで設計されたNVIDIA A100は、NVIDIAデ ータセンタープラットフォームのエンジンです。A100は、前世代と比較して最大20倍のパフォーマンスを発揮し、7つのGPUインスタンスに分割して、変化する需要に合わせて動的に調整できます。80GB のメモリを搭載した新しい A100 は、毎秒1.9テラバイト(TB/秒)超えの高速メモリ帯域幅を実現し、大規模なモデルやデータセットに対して解を得るまでの時間を短縮します。
ディープラーニング トレーニング
最大級のモデルで最大 3 倍高速な AI トレーニング
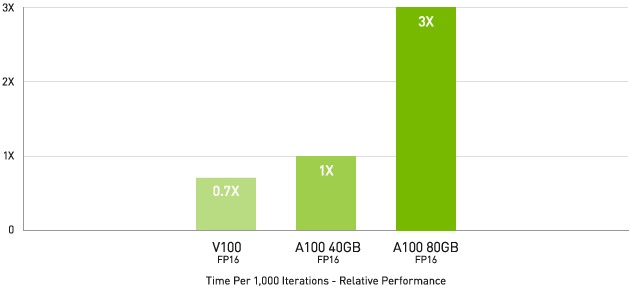
DLRM on HugeCTR framework, precision = FP16 | NVIDIA A100 80GB batch size = 48 | NVIDIA A100 40GB batch size = 32 | NVIDIA V100 32GB batch size = 32.
対話型 AI といった次のレベルの課題に挑む AI モデルは、爆発的に複雑化しています。モデルのトレーニングには、大規模な計算処理能力とスケーラビリティが必要になります。
NVIDIA A100 のTensor コアと Tensor Float (TF32) を利用することで、NVIDIA Volta と比較して最大 20 倍のパフォーマンスがコードを変更することなく得られます。加えて、Automatic Mixed Precision と FP16 の活用でさらに 2 倍の高速化が可能になります。NVIDIA® NVLink®、NVIDIA NVSwitch™、PCI Gen4、NVIDIA® Mellanox® InfiniBand®、NVIDIA Magnum IO™ SDK と組み合わせることで、数千個もの A100 GPU まで拡張できます。
2,048 基の A100 GPU という大規模な環境で、BERT などのトレーニング ワークロードを、世界記録となる 1 分未満で解決できます。
ディープラーニング レコメンデーション モデル (DLRM) といった大きなデータ テーブルを持つ最大級のモデルの場合、A100 80GB であれば、ノードあたり最大 1.3 TB の統合メモリに到達し、A100 40GB の最大 3 倍のスループットの増加が可能です。
NVIDIA は、AI トレーニングの業界標準ベンチマークであるMLPerfで複数のパフォーマンス記録を打ち立て、そのリーダーシップを確立しました。
ディープラーニング推論
A100 には、推論ワークロードを最適化する画期的な機能が導入されています。FP32 から INT4 まで、あらゆる精度を加速します。マルチインスタンス GPU (MIG) テクノロジでは、1 個の A100 で複数のネットワークを同時に動作できるため、コンピューティング リソースの使用率が最適化されます。また、構造化スパース性により、A100 による数々の推論性能の高速化に加え、さらに最大 2 倍のパフォーマンスがもたらされます。
BERT などの最先端の対話型 AI モデルでは、A100 は推論スループットを CPU の最大 249 倍に高めます。
メモリ容量の大きな A100 80GB では各 MIG のサイズが 2 倍になります。自動音声認識用の RNN-T といった、バッチサイズが制約された非常に複雑なモデルでは、A100 40GB に比べて最大 1.25 倍のスループットが得られます。
市場をリードする NVIDIA のパフォーマンスはMLPerf 推論 推論で実証されました。A100 は 20 倍のパフォーマンスを実現し、そのリードをさらに広げます。
CPU と比較して最大 249 倍高速なAI 推論パフォーマンス
BERT 大規模推論
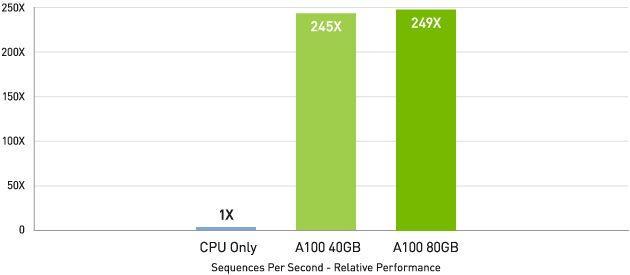
BERT-Large Inference | CPU only: Dual Xeon Gold 6240 @ 2.60 GHz, precision = FP32, batch size = 128 | V100: NVIDIA TensorRT™ (TRT) 7.2, precision = INT8, batch size = 256 | A100 40GB and 80GB, batch size = 256, precision = INT8 with sparsity.
A100 40GB と比較して最大 1.25 倍高速なAI 推論パフォーマンス
RNN-T 推論: 単一のストリーム
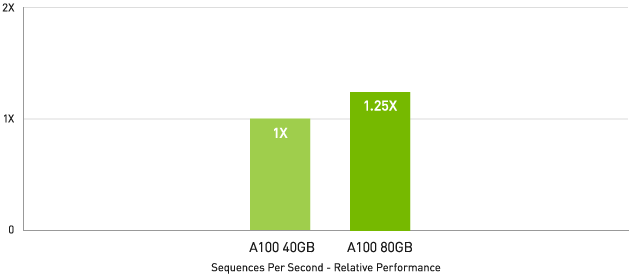
MLPerf 0.7 RNN-T measured with (1/7) MIG slices. Framework: TensorRT 7.2, dataset = LibriSpeech, precision = FP16.
ハイパフォーマンス コンピューティング
次世代の発見を解き明かすため、科学者たちは、私たちを取り巻いている世界をより良く理解するために、シミュレーションに関心を向けています。
NVIDIA A100 は、GPU の導入以降で最大のHPCパフォーマンスの飛躍を実現するために、Tensor コアを導入しています。80 GB の最速の GPU メモリと組み合わせることで、研究者は 10 時間かかる倍精度シミュレーションをA100 で 4 時間たらすに短縮できます。HPC アプリケーションで TF32 を活用すれば、単精度の密行列積演算のスループットが最大 11 倍向上します。
大規模データセットを扱う HPC アプリケーションでは、メモリが追加された A100 80GB により、マテリアル シミュレーションの Quantum Espresso において最大 2 倍のスループットの増加を実現します。この膨大なメモリと前例のないメモリ帯域幅により、A100 80GB は次世代のワークロードに最適なプラットフォームとなっています。
4 年間で 11 倍の HPC パフォーマンス
上位 HPC アプリケーション
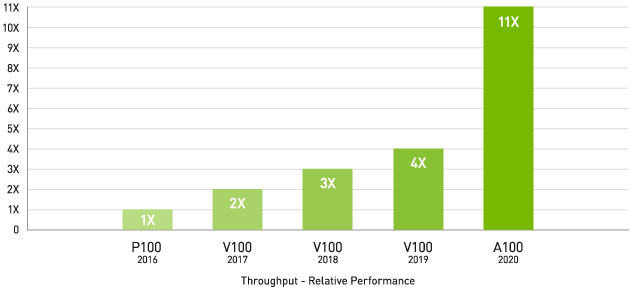
Geometric mean of application speedups vs. P100: Benchmark application: Amber [PME-Cellulose_NVE], Chroma [szscl21_24_128], GROMACS [ADH Dodec], MILC [Apex Medium], NAMD [stmv_nve_cuda], PyTorch (BERT-Large Fine Tuner], Quantum Espresso [AUSURF112-jR]; Random Forest FP32 [make_blobs (160000 x 64 : 10)], TensorFlow [ResNet-50], VASP 6 [Si Huge] | GPU node with dual-socket CPUs with 4x NVIDIA P100, V100, or A100 GPUs.
HPC アプリケーションで最大 1.8 倍高速なパフォーマンス
Quantum Espresso
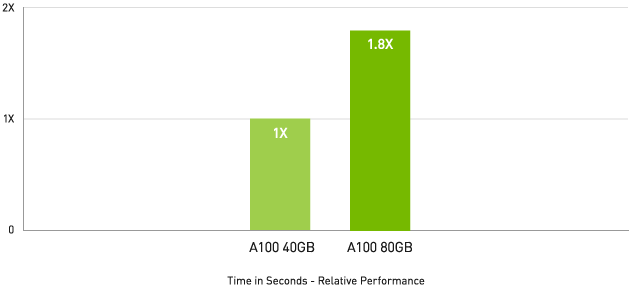
Quantum Espresso measured using CNT10POR8 dataset, precision = FP64.
ハイパフォーマンス データ分析
ビッグ データ分析ベンチマークでCPUより最大83倍、A1004GBより2倍高速
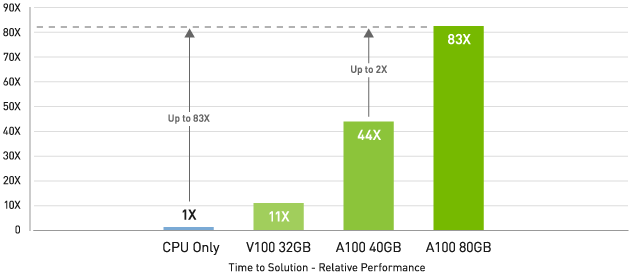 Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | CPU: Intel Xeon Gold 6252 2.10 GHz, Hadoop | V100 32GB, RAPIDS/Dask | A100 40GB and A100 80GB, RAPIDS/Dask/BlazingSQL
Big data analytics benchmark | 30 analytical retail queries, ETL, ML, NLP on 10TB dataset | CPU: Intel Xeon Gold 6252 2.10 GHz, Hadoop | V100 32GB, RAPIDS/Dask | A100 40GB and A100 80GB, RAPIDS/Dask/BlazingSQL
データ サイエンティストは、大量のデータセットを分析し、可視化し、インサイトに変えられる能力を求めています。しかしながら、スケールアウト ソリューションは行き詰まることが多々あります。複数のサーバー間でデータセットが分散されるためです。
A100 を搭載したアクセラレーテッド サーバーなら、大容量メモリ、2 TB/秒を超えるメモリ帯域幅、NVIDIA® NVLink® と NVSwitch™ によるスケーラビリティに加えて、必要な計算処理能力を提供し、データ分析ワークロードに対応することができます。InfiniBand、NVIDIA Magnum IO™ 、オープンソース ライブラリの RAPIDS™ スイート (GPU 活用データ分析用の RAPIDS Accelerator for Apache Spark を含む) と組み合わせることで、NVIDIA データ センター プラットフォームは前例のないレベルのパフォーマンスと効率性で大規模なデータ分析ワークロードを高速化します。
A100 80GB はビッグ データ分析ベンチマークで、CPU の 83 倍高いスループット、A100 40GB では 2 倍高いスループットでインサイトをもたらします。データセット サイズが爆発的に増える昨今のワークロードに最適です。
企業で効率的に利用
マルチインスタンス GPU (MIG) による 7 倍の推論スループット
BERT 大規模推論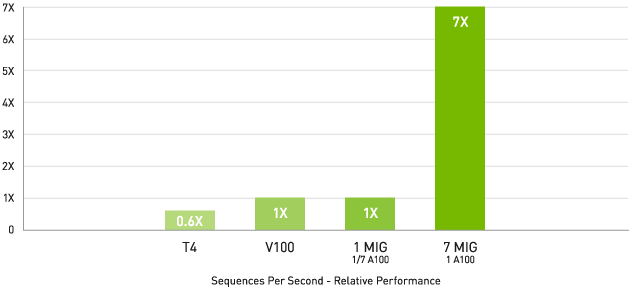 BERT Large Inference | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = INT8 with sparsity.
BERT Large Inference | NVIDIA TensorRT™ (TRT) 7.1 | NVIDIA T4 Tensor Core GPU: TRT 7.1, precision = INT8, batch size = 256 | V100: TRT 7.1, precision = FP16, batch size = 256 | A100 with 1 or 7 MIG instances of 1g.5gb: batch size = 94, precision = INT8 with sparsity.
A100 とMIGの組み合わせにより、GPU 活用インフラストラクチャを最大限に利用できます。MIG を利用することで、A100 GPU を 7 つもの独立したインスタンスに分割できます。複数のユーザーが GPU アクセラレーションを利用できます。A100 40GB では、各 MIG インスタンス に最大 5GB まで割り当てることができ、A100 80GB のメモリ容量が増えたことで、そのサイズは 2 倍の 10GB になります。
MIG は、Kubernetes、コンテナー、ハイパーバイザーベースのサーバー仮想化. と連動します。MIG を利用することで、インフラストラクチャ管理者はあらゆるジョブに適切なサイズの GPU を提供し、サービスの品質 (QoS) を保証できます。アクセラレーテッド コンピューティング リソースをすべてのユーザーに届けることが可能です。
仕様
| CUDA Cores | 6912 |
|---|---|
| Tensor Cores | 432(第3世代) |
| RT Cores | N/A |
| GPU クロック(MHz) | ベース: 1065 |
| ブースト: 1410 | |
| メモリ容量 | 80GB HBM2e |
| メモリインターフェイス(bit) | 5120 |
| メモリクロック(MHz) | 1512 |
| メモリ帯域幅(GB/s) | 1935 |
| 対応拡張スロット | PCI Express 4.0 x16 |
| コンピュートAPI | NVIDIA CUDA / DirectCompute / OpenCL / OpenACC |
| 出力コネクタ | N/A |
| グラフィックスAPI | N/A |
| 適合規格 | WHQL / ISO9241 / EU RoHS / JIG / REACH / HF / WEEE / RCM / BSMI /CE / FCC / ICES / KC / cUL, UL / VCCI |
| 対応OS | Windows Server 2019, Windows Server 2022, Windows10 64bit(*1) , Windows11, Linux 64bit |
| 最大消費電力 | 300 W |
| 補助電源コネクタ仕様 | CPU 8pin(*2) |
| 外形寸法(mm) ブラケット含まず |
267.7 x 111.2、ATX、2スロットサイズ |
| 付属品 | PCIe 8pin×2 – CPU 8pin x1 補助電源変換ケーブル × 1 |
(*1) バージョン1809以降を推奨
(*2) 6ピン/8ピンのPCI Express用補助電源とCPU 8ピン補助電源コネクタは形状が異なります。
必要動作環境
本製品はNVIDIA社の認定システムのみの動作保証となります。
詳しくは下記リンク先の情報をご確認ください。
https://www.nvidia.com/ja-jp/data-center/data-center-gpus/qualified-system-catalog/
理論演算性能値
| FP64 (TFLOPS) | 9.7 | |
|---|---|---|
| FP64 Tensor Core (TFLOPS) | 19.5 | |
| FP32 (TFLOPS) | 19.5 | |
| FP16 (TFLOPS) | 78 | |
| TF32 Tensor Core (TFLOPS) | 156 | 312(*3) |
| BFLOAT16 Tensor Core (TFLOPS) | 312 | 624(*3) |
| FP16 Tensor Core (TFLOPS) | 312 | 624(*3) |
| INT8 Tensor Core (TOPS) | 624 | 1248(*3) |
| INT4 Tensor Core (TOPS) | 1248 | 2496(*3) |
(*3) 構造化スパースを適用
対応機能
| Multi-Instance GPU Support (Max Instance) | 〇(7) |
|---|---|
| ECC 対応 | 〇 |
| NVLink 対応 | 600GB/s (第3世代) |
製品内容
- NVIDIA® A100 80GB
- 製品保証書
保証期間
- 3年間保証
品番
| 製品名 | NVIDIA A100 80GB NC | NVIDIA A100 80GB |
|---|---|---|
| 型番 | ETSA100-80GER2 | ETSA100-80GER |
| JANコード | 4524076071390 | 4524076071253 |
■本製品は順次製品名に「NC」が付くものへ置き換わり、「NC」が付かないものは在庫が無くなり次第終息とさせていただきます。
■製品名に「NC」が付くものは、製品の機能からCECが削除されます。
※CECとは
CECはGPUボード上のセカンダリRoT(root of trust)のことで、 デバイスの信頼性を保証するためのハードウェア / ソフトウェアコンポーネントを指します。
また、CECの廃止に伴い以下の機能が提供されなくなります。
- ファームウェア署名キー
- ファームウェアの正当性証明
- Out-of-band ファームウェアアップデート
オプション
-

NVLink Bridge 2-Slot (for Ampere)
NVIDIA NVLink Bridge 2-Slot
(for Ampere) Retail
ELSA型番:P3412
JANコード:4524076030311
価格
- オープンプライス
© 2021 NVIDIA Corporation. All Rights Reserved. NVIDIA, NVIDIA logo, Tesla, and CUDA are registered trademarks and/or trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.